分代ZGC
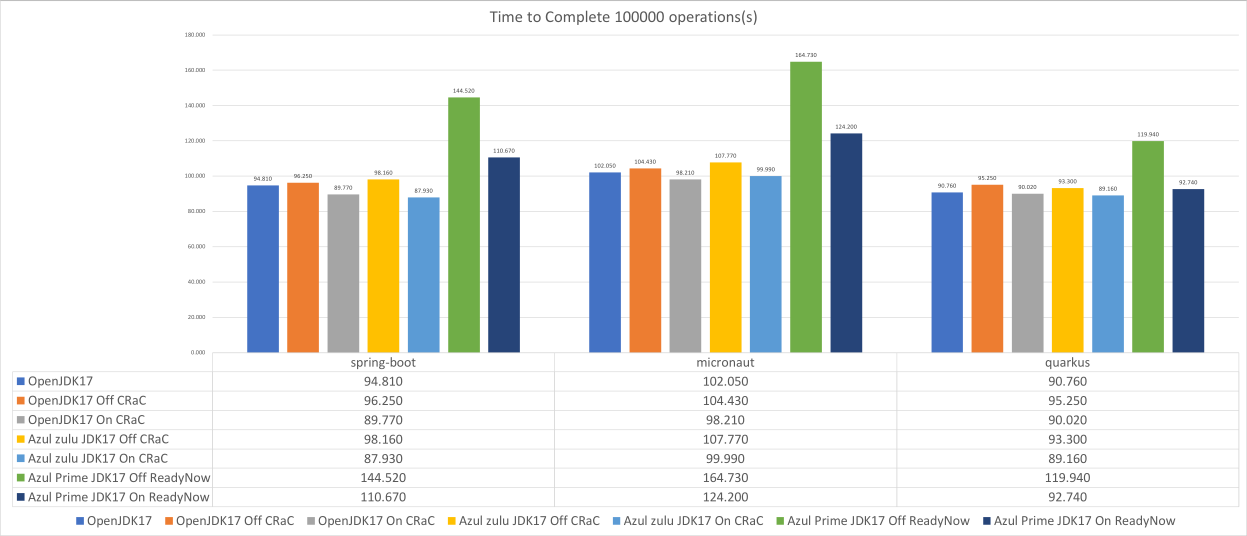
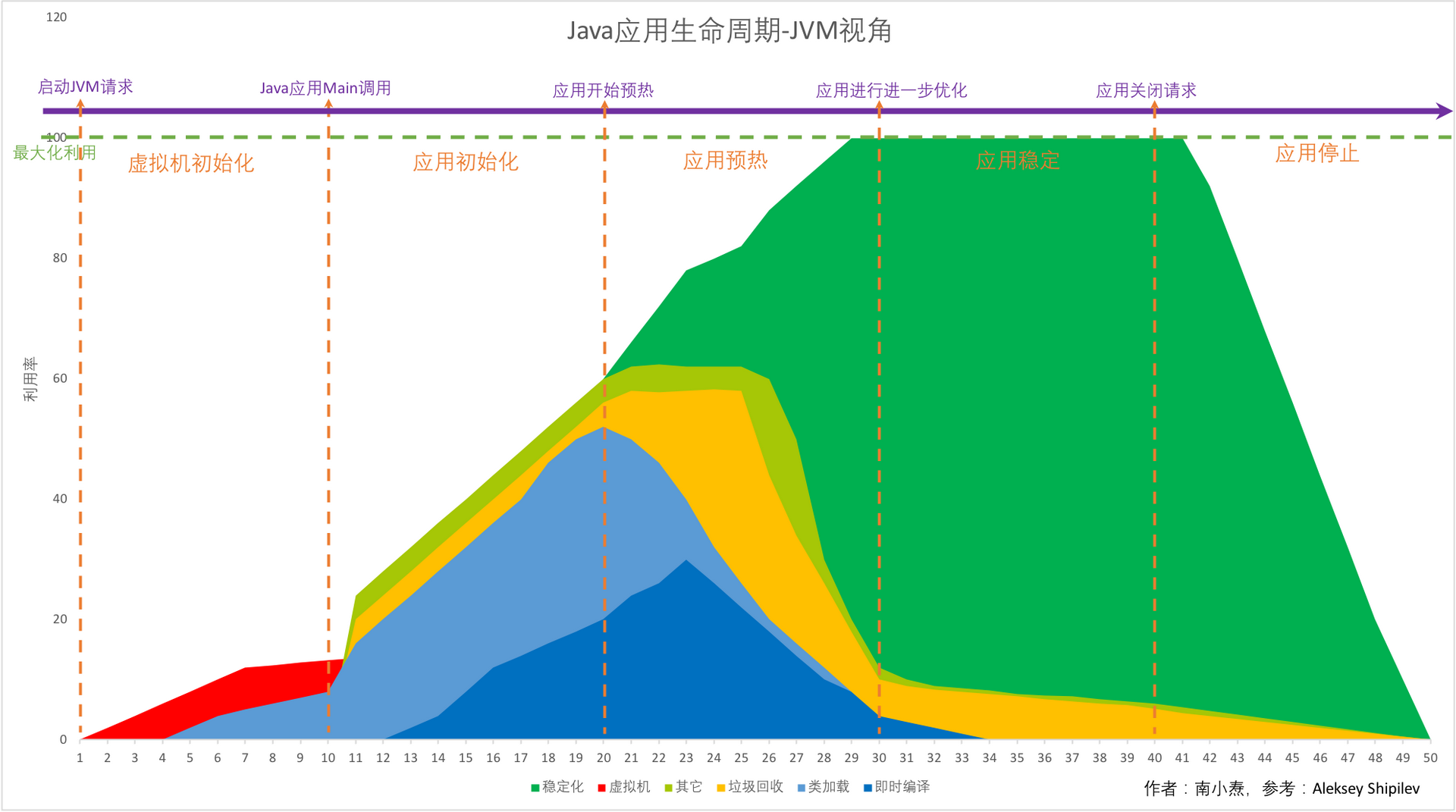
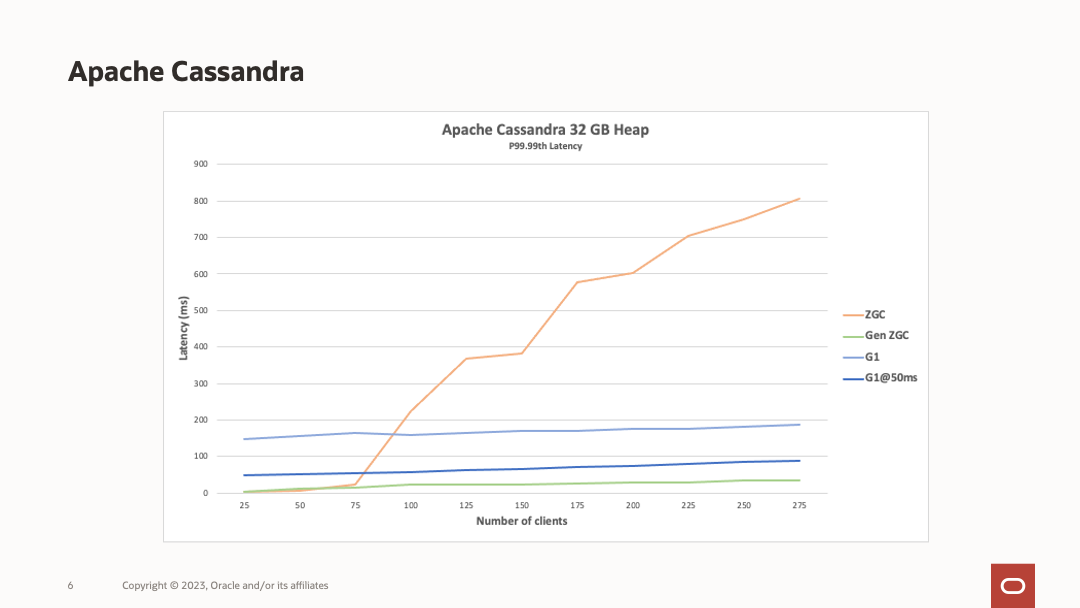
1.分代ZGC 是否在openjdk的21版本里面完全实现?还是部分实现? 完全实现 2.分代ZGC和普通的ZGC的主要区别在哪里? 普通的ZGC:每次回收所有对象 分代ZGC:分代进行回收 我们相信,Generational ZGC 将比其前身更适合大多数用例。 由于资源使用率较低,某些工作负载甚至可能会通过分代 ZGC 获得吞吐量提升。 例如,当运行 Apache Cassandra 基准测试时,与非分代 ZGC 相比,分代 ZGC 需要四分之一的堆大小,但却实现了四倍的吞吐量,同时仍将暂停时间保持在一毫秒以下。 某些工作负载本质上是非分代的,并且可能会出现轻微的性能下降。 我们认为,这是一组足够小的工作负载,不足以证明长期维护两个单独版本的 ZGC 的成本是合理的。 另一种开销来源是功能更强大的 GC 屏障。 我们预计其中大部分将被不必频繁收集老一代对象的收益所抵消。 另一个额外的开销来源是同时运行两个垃圾收集器。 我们需要确保平衡它们的调用率和 CPU 消耗,以便它们不会过度影响应用程序。 正如 GC 开发的正常情况一样,未来的改进和优化将由基准测试和用户反馈驱动。 即使在第一个版本发布之后,我们也打算继续改进 Generational ZGC。 3.分代ZGC在OpenJDK的开发过程中,他们开发的时间跨度,研发人员等等信息。主要目的是希望能对这个工作的大概effort有一个评估。 3.1.JDK21-日程 Schedule 2023/06/08 Rampdown Phase One (fork from main line-JDK17-LTS) 2023/07/20 Rampdown Phase Two 2023/08/10 Initial Release Candidate 2023/08/24 Final Release Candidate 2023/09/19 General Availability Amost 103days 3.2.分代ZGC-研发人员 Co-authored-by: Stefan Karlsson Co-authored-by: Erik Österlund Co-authored-by: Axel Boldt-Christmas Co-authored-by: Per Liden Co-authored-by: Stefan Johansson Co-authored-by: Albert Mingkun Yang Co-authored-by: Erik Helin Co-authored-by: Roberto Castañeda Lozano Co-authored-by: Nils Eliasson Co-authored-by: Martin Doerr Co-authored-by: Leslie Zhai Co-authored-by: Fei Yang Co-authored-by: Yadong Wang Reviewed-by: eosterlund, aboldtch, rcastanedalo 13人...